Omni-Reward: Towards Generalist Omni-Modal Reward Modeling with Free-Form Preferences
Omni-Reward: Towards Generalist Omni-Modal Reward Modeling with Free-Form Preferences
Abstract
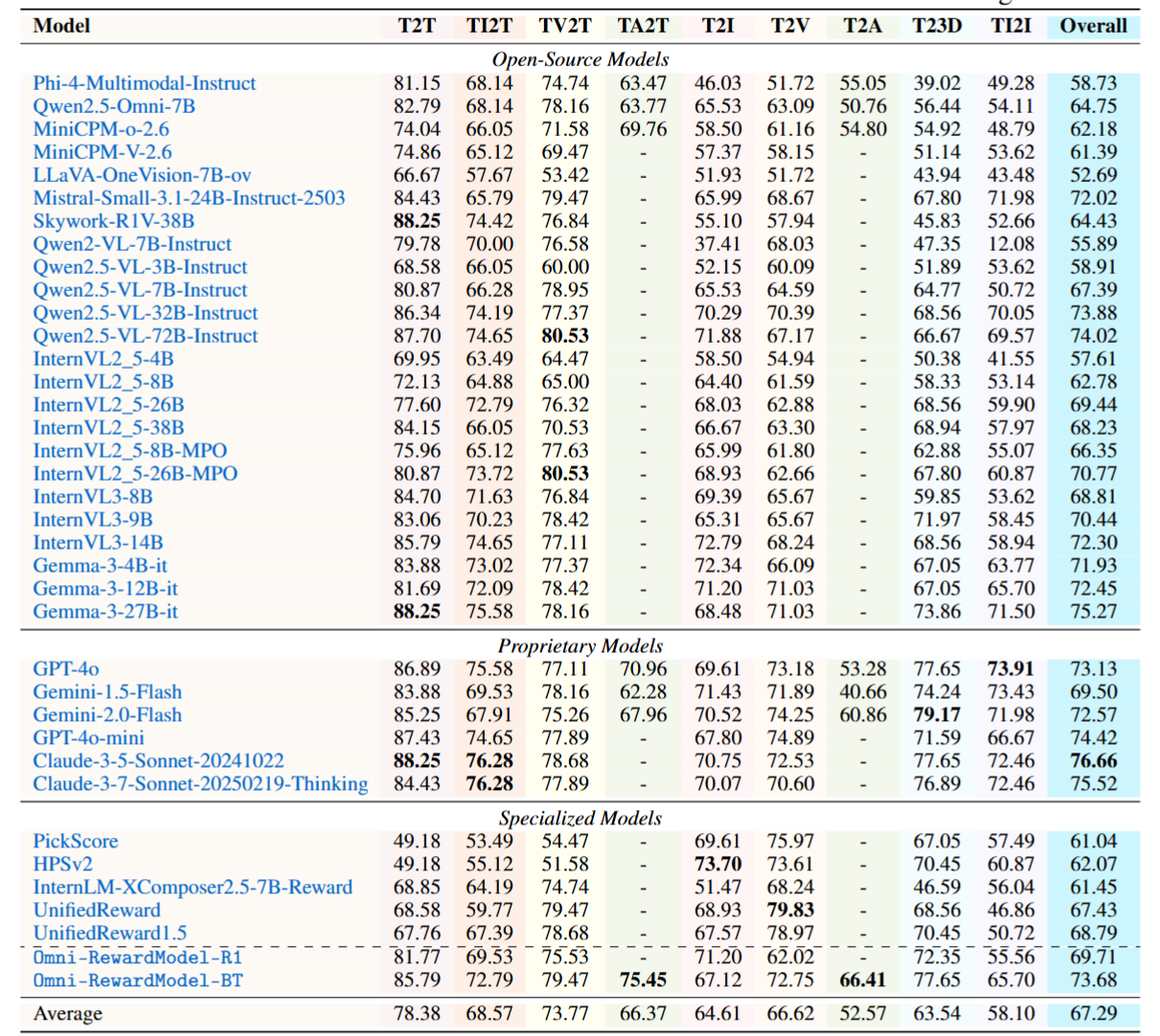
Reward models (RMs) play a critical role in aligning AI behaviors with human preferences, yet they face two fundamental challenges: (1) Modality Imbalance, where most RMs are mainly focused on text and image modalities, offering limited support for video, audio, and other modalities; and (2) Preference Rigidity, where training on fixed binary preference pairs fails to capture the complexity and diversity of personalized preferences. To address the above challenges, we propose Omni-Reward, a step toward generalist omni-modal reward modeling with support for free-form preferences, consisting of: (1) Evaluation: We introduce Omni-RewardBench, the first omni-modal RM benchmark with free-form preferences, covering nine tasks across five modalities including text, image, video, audio, and 3D; (2) Data: We construct Omni-RewardData, a multimodal preference dataset comprising 248K general preference pairs and 69K instruction-tuning pairs for training generalist omni-modal RMs; (3) Model: We propose Omni-RewardModel, which includes both discriminative and generative RMs, and achieves strong performance on Omni-RewardBench as well as other widely used RM benchmarks.
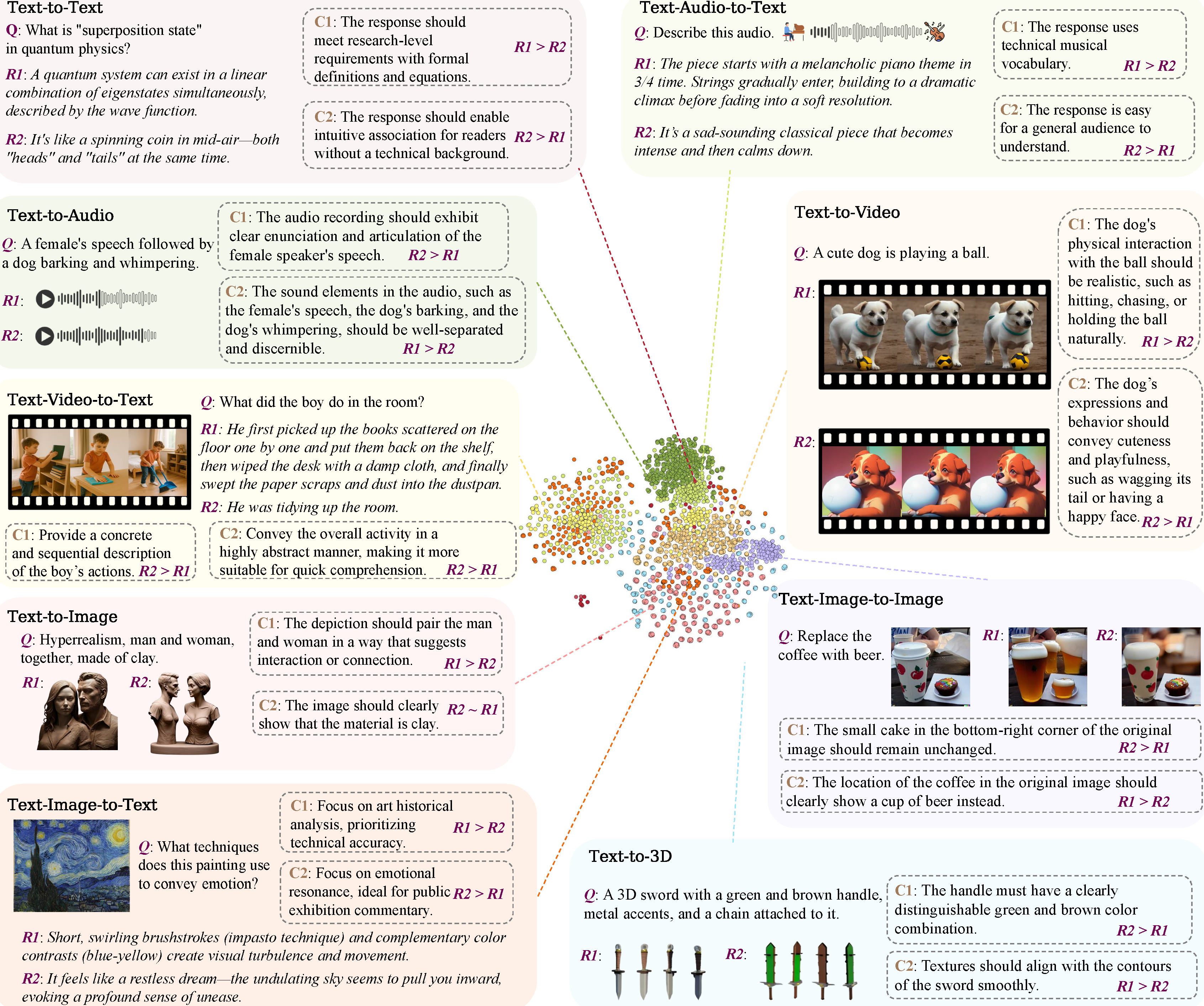
Omni-RewardBench
Omni-RewardModel
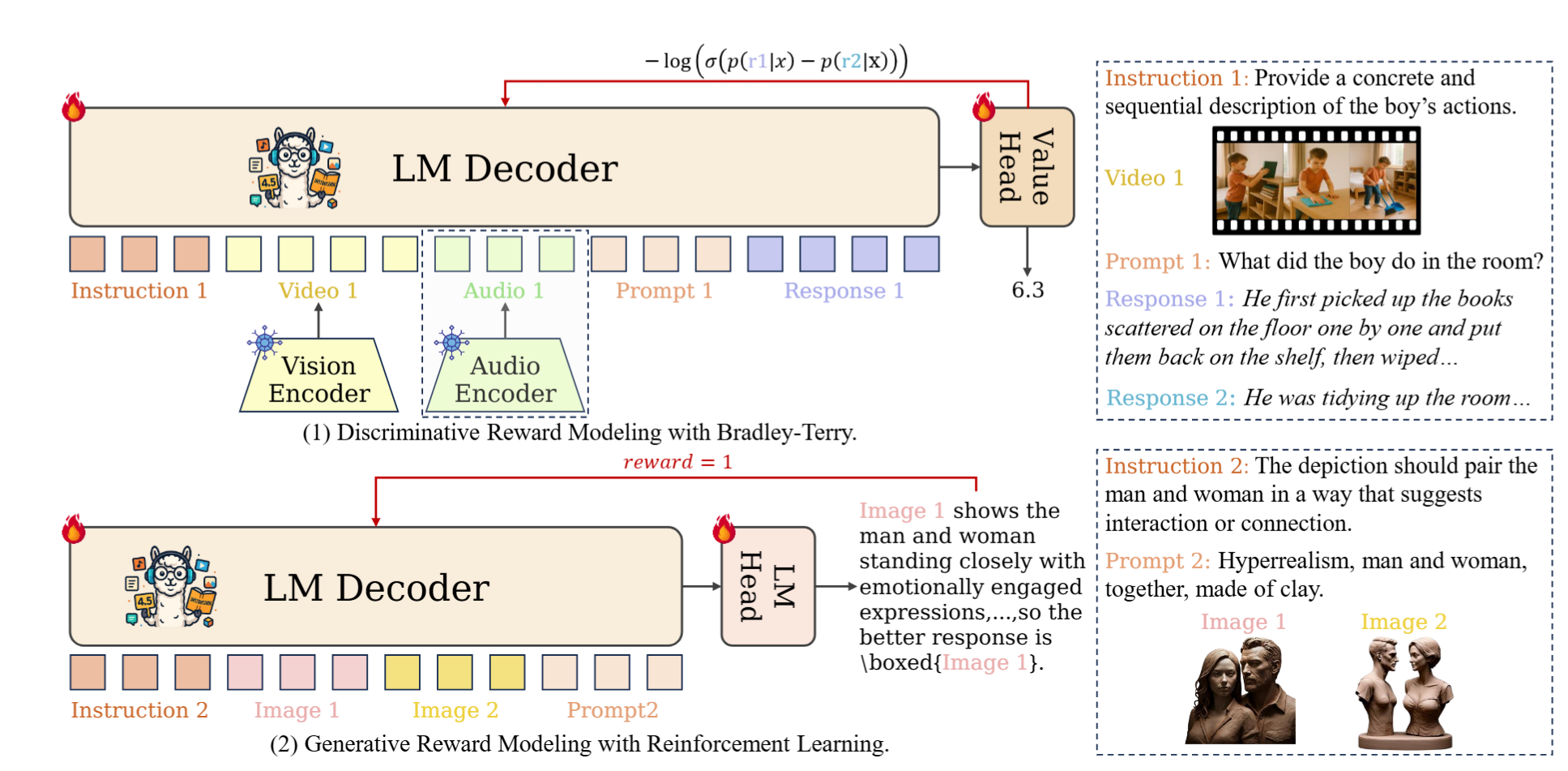
Experimental Results
W/ Tie Setting
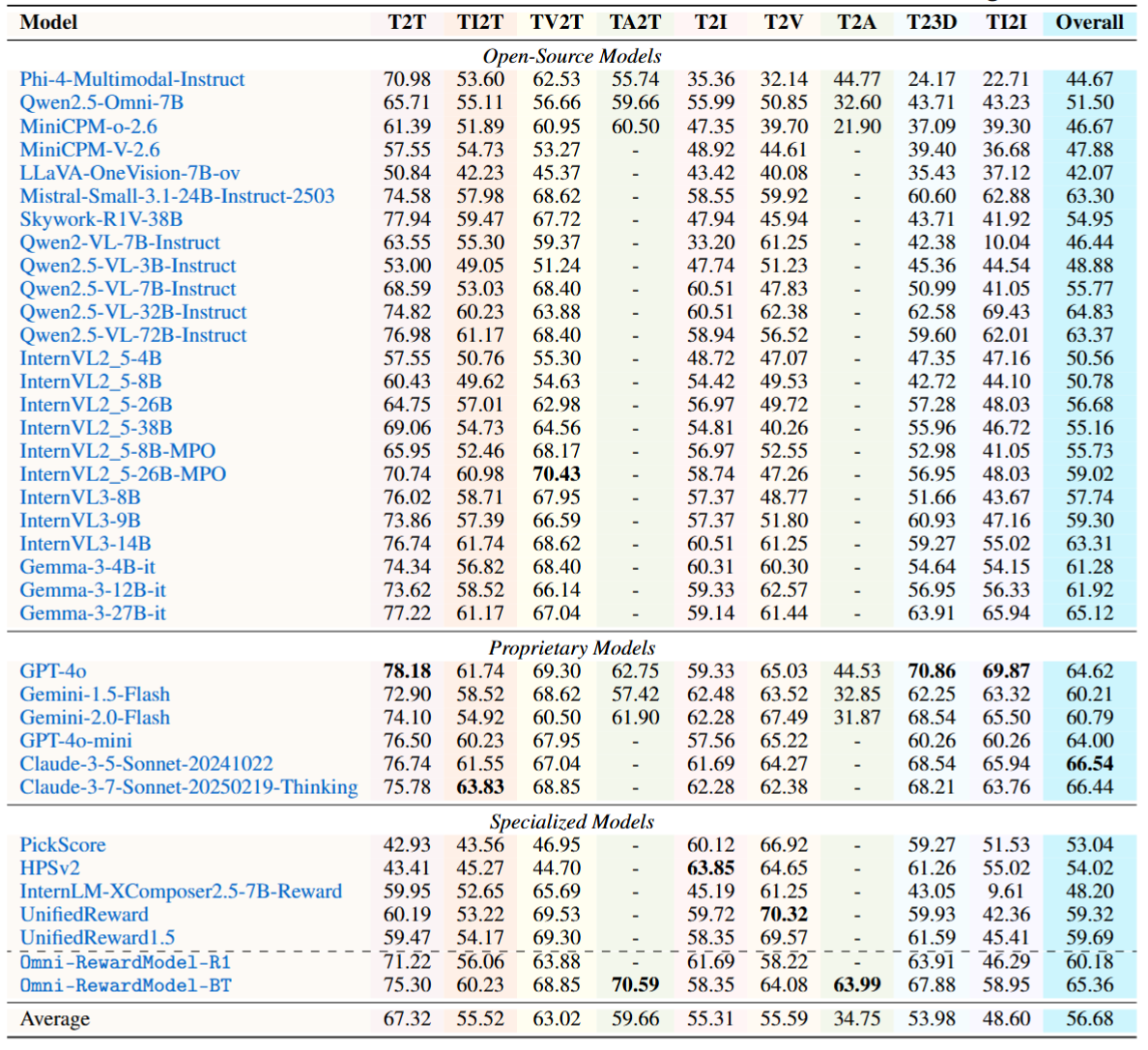
W/o Tie Setting